tblsで生成したテーブル定義のDescriptionをGPTで補完する
自社では @k1low が開発しているtblsで各種データストアのテーブル定義をドキュメンテーションしています。
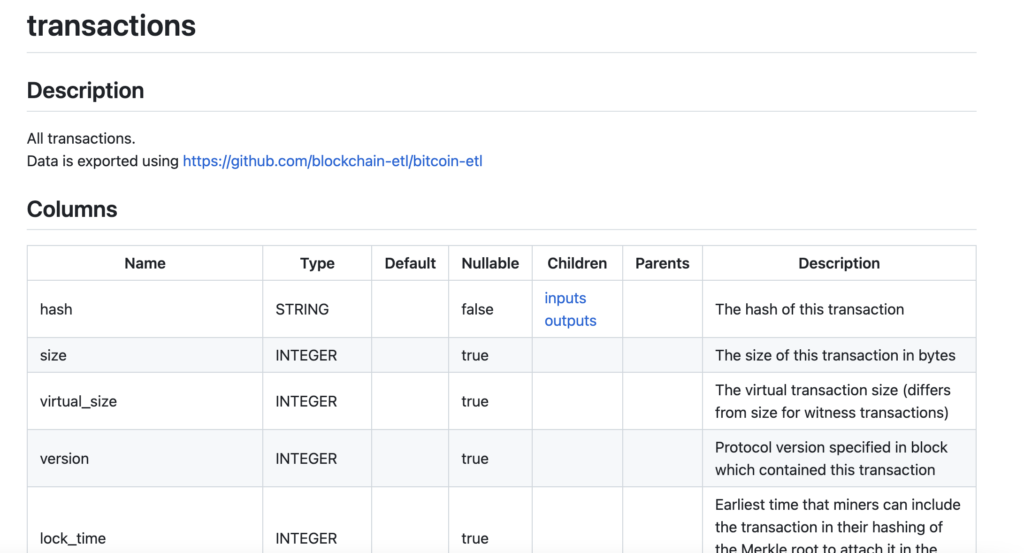
tblsを利用するとこういうマークダウンやER図が出力できます。
https://github.com/k1LoW/tbls/blob/main/sample/bigquery_crypto_bitcoin/transactions.md
公式リポジトリより引用
非常に便利なのですが、昔からあるテーブルなどは、Descriptionが埋まっておらず、一見なんのデータが入っているカラムなのかわからないことがあるので、BigQueryのデータを対象に、サンプルレコードをとってきて、秘匿情報をマスクしてOpenAIのAPIを実行する実装を書いてみました。なお、この実装はアイディアベースのものでまだ本番運用に耐えるものではありません。
技術要素としては秘匿情報のマスクはDLPを活用しています。ちょこちょこサンプリングしているといい感じにマスクしてくれるので結構便利です。
import glob
import os
import textwrap
import google.cloud.dlp
import openai
from google.cloud import bigquery
from google.cloud.dlp import CharsToIgnore
GCP_PROJECT = os.environ.get("GCP_PROJECT")
def extract_content(file_path):
content = ""
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
start_flag = False
for line in lines:
if "## Columns" in line:
start_flag = True
continue
if "## Relations" in line:
start_flag = False
continue
if start_flag:
content += line
return content
def mask_content(
project,
input_str,
info_types,
masking_character=None,
number_to_mask=0,
ignore_commpn=None,
):
dlp = google.cloud.dlp_v2.DlpServiceClient()
parent = f"projects/{project}"
item = {"value": input_str}
inspect_config = {"info_types": [{"name": info_type} for info_type in info_types]}
deidentify_config = {
"info_type_transformations": {
"transformations": [
{
"primitive_transformation": {
"character_mask_config": {
"masking_character": masking_character,
"number_to_mask": number_to_mask,
"characters_to_ignore": [
{"common_characters_to_ignore": ignore_commpn}
],
}
}
}
]
}
}
response = dlp.deidentify_content(
request={
"parent": parent,
"deidentify_config": deidentify_config,
"inspect_config": inspect_config,
"item": item,
}
)
return response.item.value
def get_records(dataset_id, table_id, record_limit=10):
client = bigquery.Client()
table_ref = client.dataset(dataset_id).table(table_id)
table = client.get_table(table_ref)
query = f"SELECT * FROM `{table.project}.{table.dataset_id}.{table.table_id}` LIMIT {record_limit}"
query_job = client.query(query)
return query_job.result()
def replace_columns_to_relations(file_path, replacement_content):
with open(file_path, "r") as file:
content = file.read()
start_tag = "## Columns"
end_tag = "## Relations"
# 置き換える範囲を見つける
start = content.find(start_tag) + len(start_tag)
end = content.find(end_tag)
# 置き換える範囲を指定の値に置き換える
modified_content = (
content[:start]
+ "\n"
+ replacement_content
+ "\n"
+ "*Descritpion列はGPT-4で生成したものです*"
+ "\n"
+ content[end:]
)
# 置き換えた内容をファイルに書き戻す
with open(file_path, "w") as file:
file.write(modified_content)
def has_done(data):
lines = data.strip().split("\n")
for line in lines[2:]:
# split the line into cells
cells = line.split("|")
return cells[-1].strip() != ""
def main():
target_directory = f"{GCP_PROJECT}/*/*.md"
file_paths = glob.glob(target_directory)
datasets = []
for file_path in file_paths:
print(f"Processing file: {file_path}")
paths = file_path.split(os.sep)
content = extract_content(file_path)
dataset = paths[1]
if "test" in dataset:
continue
table = paths[2].split(".")[0]
datasets.append(
{
"dataset": dataset,
"table": table,
"content": content,
"file_path": file_path,
}
)
for dataset in datasets:
if has_done(dataset["content"]):
print(f"Already done. Skip. {dataset['file_path']}")
continue
masked_rows = []
for row in get_records(dataset["dataset"], dataset["table"], 10):
masked_rows.append(
mask_content(
GCP_PROJECT,
",".join([str(value)[:50] for value in row]),
[
"PERSON_NAME",
"EMAIL_ADDRESS",
"PHONE_NUMBER",
"CREDIT_CARD_NUMBER",
"LOCATION",
"MALE_NAME",
"FEMALE_NAME",
"AUTH_TOKEN",
"AWS_CREDENTIALS",
"BASIC_AUTH_HEADER",
"GCP_API_KEY",
"ENCRYPTION_KEY",
"GCP_CREDENTIALS",
"OAUTH_CLIENT_SECRET",
"PASSWORD",
"JAPAN_BANK_ACCOUNT",
],
masking_character="*",
ignore_commpn=CharsToIgnore.CommonCharsToIgnore.PUNCTUATION.value,
)
)
context = """
## 入力仕様
- あるテーブルの構造をマークダウンで表現したものと、そのテーブルのサンプルデータ10件をCSVで入力します。
## 指示
- テーブルの構造のマークダウンのDescriptionを埋めて、マークダウンで定義されたテーブルの修正後の内容だけを返却してください。
- 日本語で回答してください。
## テーブルの構造
{table_struct}
## サンプルデータ
{sample_data}
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{
"role": "user",
"content": textwrap.dedent(context).format(
table_struct=dataset["content"],
sample_data="\n".join(masked_rows),
),
},
],
)
print("result: ", response.choices[0]["message"]["content"])
replace_columns_to_relations(
dataset["file_path"], response.choices[0]["message"]["content"]
)
print(f"Done. {dataset['file_path']}")
if __name__ == "__main__":
main()
詳細は実装見てくれ以外の何物でもないのですが、こんな感じでAIにデータを意味づけしてもらうの結構便利だと思うので、試してみてください。